5.2 Supervised Learning und Reinforcement Learning
Schauen wir uns nun näher an, wie KI-Chatbots wirklich funktionieren. Beim klassischen Programmieren geben Menschen genaue Regeln vor, wie sich der Computer verhalten soll, z.B. "Wenn der User fragt, wie es Dir geht, antworte 'gut'." Dieses Verfahren stößt bei menschlichen Konversationen jedoch schnell an seine Grenzen.
Anders ist die Vorgehensweise beim Maschinellen Lernen, einem Teilgebiet der KI: Hier startet der Computer ohne Vorwissen und verbessert sich in einer Aufgabe durch eigenes Ausprobieren & Feedback. Bei KI-Chatbots kommen die Verfahren Supervised Learning und Reinforcement Learning zum Einsatz, die weiter unten noch näher erläutert werden.
Die Daten als Grundlage des Wissens einer KI kommen aus verschiedenen Quellen und sind essenziell für den Trainingsprozess. Es sind große Mengen an Trainingsdaten notwendig, um einem KI-Modell zu helfen, Muster und Zusammenhänge zu erkennen. Diese Daten können aus öffentlichen Datensätzen, speziell erstellten Datensätzen oder realen Datenquellen stammen.
Der Chatbot ChatGPT zum Beispiel erhält seine Daten aus einer Vielzahl von Quellen, die für das Training eines großen Sprachmodells zusammengestellt wurden. Dieses Training basiert auf einer umfangreichen Grundlage von Textdaten, der Folgendes umfassen kann:
-
Literarische Werke, Lehrbücher und andere schriftliche Materialien.
-
Artikel, Blogs, Forenbeiträge und andere schriftliche Inhalte aus dem Internet.
-
Veröffentlichungen aus verschiedenen wissenschaftlichen Disziplinen.
-
Konversationen und Dialoge, die helfen, das Modell auf natürliche Sprachinteraktionen zu trainieren.
-
Nachrichtenartikel, technische Dokumentationen, gesetzliche Texte und mehr, um eine breite Palette von Sprachstilen und -kontexten abzudecken.
Diese Daten dienen dem Training eines Modells. Hier kommt das schon erwähnte Supervised Learning (Überwachtes Lernen) zum Einsatz. Ein Modell wird mithilfe von Datensätzen trainiert, die für jede Eingabe einen passenden Ausgabewert beinhalten. Der Algorithmus lernt, basierend auf diesen Daten, eine Beziehung zwischen den Eingaben und den Ausgaben herzustellen, sodass er auf unbekannte Daten Vorhersagen treffen kann. Bei KI-Chatbots erhält das Modell als Eingabe einen Textausschnitt und versucht, das nächste Wort für den Textausschnitt zu raten.
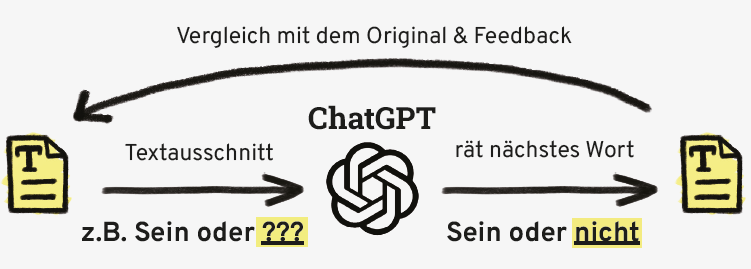
Quelle: https://articlett.schule unter der Lizenz CC BY-NC-SA 4.0 (http://creativecommons.org/licenses/by-nc-sa/4.0/)
Das Modell lernt also anhand von Beispielen, Text zu generieren und auf Anfragen zu antworten. Um sicherzustellen, dass das Modell genaue und zuverlässige Informationen liefert und um die Eingabe von unerwünschten oder voreingenommenen Informationen zu minimieren, müssen die Daten, mit denen Trainiert wird, sorgfältig ausgewählt werden.
Der Trainingsprozess ist mehrstufig: In einem weiteren Schritt wird das trainierte Modell validiert, indem es mit neuen, unbekannten Daten getestet wird, um zu sehen, wie gut es in der Praxis funktioniert.
Weiterhin kommt Reinforcement Learning (Verstärkendes Lernen) zum Einsatz, also Lernen durch Belohnung und Bestrafung. Nutzer bewerten dabei die Antworten, die KI-Chatbots geben, wobei ChatGPT darauf trainiert ist, hilfreiche Antworten zu geben, nicht korrekte.

Quelle: https://articlett.schule unter der Lizenz CC BY-NC-SA 4.0 (http://creativecommons.org/licenses/by-nc-sa/4.0/)
In folgendem Video wird nochmals auf ansprechende Art und Weise zusammengefasst, was große Sprachmodelle (Large Language Models, LLMs) sind, wie sie funktionieren, und was übliche Einsatzgebiete sind.
Quelle: https://www.youtube.com/watch?v=5sLYAQS9sWQ
Quellen und Ressourcen
 Wer tiefer eintauchen möchte in die Welt von neuronalen Netzwerken findet beispielsweise auf diesen Youtube-Kanälen nähere Informationen: https://www.youtube.com/watch?v=aircAruvnKk oder https://www.youtube.com/watch?v=ER2It2mIagI
Wer tiefer eintauchen möchte in die Welt von neuronalen Netzwerken findet beispielsweise auf diesen Youtube-Kanälen nähere Informationen: https://www.youtube.com/watch?v=aircAruvnKk oder https://www.youtube.com/watch?v=ER2It2mIagI
Trotz der gezielten Auswahl von Daten, mit denen Modelle trainiert werden, sind in der Vergangenheit Schwächen in den Ausgaben der Modelle sichtbar geworden, weshalb wir uns jetzt mit dem Thema Ethik und Herausforderungen beschäftigen. In dieser komplexen Welt, in der nicht alles sofort durchschaubar ist, steht die Verantwortung der Personen, die mit der KI arbeiten, an erster Stelle.